Don’t mistake OpenAI Codex for a programmer
In a new paper, researchers at OpenAI have revealed details about Codex, a deep learning model that generates software source code. Codex powers Copilot, an “ AI pair programmer ” tool developed jointly by OpenAI and GitHub. Copilot is currently available in beta test mode to a limited number of users.

The paper is a fascinating read that explains the process through which the scientists at OpenAI managed to repurpose their flagship language model GPT-3 to create Codex. But more importantly, the paper also sheds much-needed light on how far you can trust deep learning in programming.
The “no free lunch” theorem
Codex is a descendent of GPT-3 , a massive deep learning language model release last year. The complexity of deep learning models is often measured by the number of parameters they have. In general, a model’s learning capacity increases with the number of parameters. GPT-3 came with 175 billion parameters, more than two orders of magnitude larger than its predecessor, GPT-2 (1.5 billion parameters). GPT-3 was trained on more than 600 gigabytes, more than 50 times larger than GPT-2’s training dataset.
Aside from the huge increase in size, the main innovation of GPT-3 was “ few-shot learning ,” the capability to perform tasks it wasn’t trained for. The paper that introduced GPT-3 was titled “Language Models are Few-Shot Learners” and stated: “Here we show that scaling up language models greatly improves task-agnostic, few-shot performance [emphasis mine], sometimes even reaching competitiveness with prior state-of-the-art fine-tuning approaches.”
Basically, the premise was a large-enough model trained on a large corpus of text can match or outperform several models that are specialized for specific tasks.
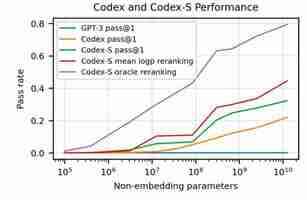
But according to the new paper by OpenAI, none of the various versions of GPT-3 were able to solve any of the coding problems used to evaluate Codex. To be fair, there were no coding samples in GPT-3’s training dataset, so we can’t expect it to be able to code. But the OpenAI scientists also tested GPT-J, a 6 billion-parameter model trained on The Pile , an 800-gigabyte dataset that includes 95 gigabytes of GitHub and 32 gigabytes of StackExchange data. Opesolved 11.4 percent of the coding problems. Codex, a version of GPT-3’s 12-billion parameter fine-tuned on 159 gigabytes of code examples from GitHub, solved 28.8 percent of the problems. A separate version of Codex, called Codex-S, which was fine-tuned through supervised learning boosted the performance to 37.7 percent (other GPT and Codex models are trained through unsupervised learning ).
Codex proves that machine learning is still ruled by the “ no free lunch ” theorem (NFL), which means that generalization comes at the cost of performance. In other words, machine learning models are more accurate when they are designed to solve one specific problem. On the other hand, when their problem domain is broadened, their performance decreases.
Codex can perform one specialized task (transforming function descriptions and signatures into source code) with high accuracy at the cost of poor natural language processing capabilities. On the other hand, GPT-3 is a general language model that can generate decent text about a lot of topics (including complicated programming concepts) but can’t write a single line of code.
Size vs cost
The experiments of OpenAI’s researchers show that the performance of Codex improved as they increased the size of the machine learning model. At 300 million parameters, Codex solved 13.2 percent of the evaluation problems against the 28.8 percent performance of the 12-billion-parameter model.
But the full version of GPT-3 is 175 billion parameters, a full order of magnitude larger than the one used to create Codex. Wouldn’t training the larger model on the Codex training data yield better results?
One probable reason for stopping at 12 billion could be the dataset size. A larger Codex model would need a larger dataset. Training it on the 159-gigabyte corpus would probably cause overfitting, where the model becomes very good at memorizing and rehearsing its training examples and very bad at dealing with novel situations. Gathering and maintaining larger datasets is an expensive and time-consuming process.
An equally vexing problem would be the cost of Codex. Aside from a scientific experiment, Codex was supposed to become the backbone of a future product that can turn in profits for a research lab that is quasi-owned by a commercial entity. As I’ve already discussed before, the costs of training and running the 175-billion GPT-3 model would make it very hard to develop a profitable business model around it.
However, a smaller but fine-tuned version of GPT-3 would be much more manageable in terms of profits and losses.
Finally, as OpenAI’s experiments show, Codex’s size/performance ratio follows a logarithmic scale. This means that performance gains gradually reduce as you increase the size of the model. Therefore, the added costs of gathering data and training and running the larger model might not be worth the small performance boost.
And note that code generation is a very lucrative market. Given the high hourly salaries of programmers, even saving a few hours’ worth of coding time per month would be enough to cover the subscription fees of Codex. In other domains where labor is less expensive, automating tasks with large language models will be more challenging from a profit and loss perspective.
Generating vs understanding code
This article was originally published by Ben Dickson on TechTalks , a publication that examines trends in technology, how they affect the way we live and do business, and the problems they solve. But we also discuss the evil side of technology, the darker implications of new tech, and what we need to look out for. You can read the original article here .
TL;DR: This AI summarizes research papers so you don’t have to
Reading scientific papers is a tough job. It might contain language and sections that you might not understand, and not all of it would be interesting to you.
My colleague Tristan is great at traversing through these papers , but I’m just a novice. So, I would want a quick summary of a research document to decide if I want to dedicate more time reading it.
Thankfully, researchers at the Allen Institute for Artificial Intelligence have developed a new model to summarize text from scientific papers, and present it in a few sentences in the form of TL;DR (Too Long Didn’t Read).
The team has rolled this model out to the Allen Institute’s Semantic Scholar search engine for papers. Currently, you’ll only see these TL;DR summaries on papers related to computer science on search results or the author’s page.
AI takes the most important parts from the abstract, introduction, and conclusion section of the paper to form the summary.
Researchers first “pre-trained” the model on the English language. Then they created a SciTLDR data set of over 5,400 summaries of computer science papers. It was further trained on more than 20,000 titles of research papers to reduce dependency on domain knowledge while writing a synopsis.
The trained model was able to summarize documents over 5,000 words in just 21 words on an average — that’s a compression ratio of 238. The researchers now want to expand this model to papers in fields other than computer science.
You can try out the AI on the Semantic Scholar search engine. Plus, you can read more about summarizing AI in this paper .
How the laws of physics could prevent us from ever meeting aliens
Where are the aliens? Italian physicist Enrico Fermi posited the idea that aliens may not exist simply because, if they did, there should be some evidence for them.

Fermi wasn’t a troll. You can believe in aliens and also recognize that science requires actionable data.
But what if both Fermi’s paradox and the alien enthusiasts are correct? What if we posit a sort of Fermi’s Alien where, like Schrodinger’s Cat, the creature exists in two paradoxical states that are simultaneously true.
Fermi’s Alien, which is something I just made up, tells us that aliens can both exist in the universe and not exist in the universe at the same time.
Let’s start with the basics. If we created a supercomputer with our most advanced algorithms and packed it into our fastest space ship, it would take the vessel about eighty-one billion one hundred eighty-four million years to reach the Milky Way’s next door neighbor .
That’s a long trip to make for some small odds. But what if we simplify things a bit. Let’s pretend that someone’s finally invented a functional warp drive and, just for kicks, let’s say we can build a spaceship capable of traveling at the speed of light in perpetuity.
Exactly how much of this great big universe that’s potentially teeming with intelligent life could we ever hope to explore?
Big Think’s Ethan Siegel recently published a fascinating visual article discussing the speed of light as it relates to our position in the universe. And, according to them, about 94% of everything is out of our reach.
You see, the universe isn’t a giant bubble in which Earth exists as a point on a 3D map. The idea of “location” is a moving target, so to speak.
That’s because the universe is expanding. This makes visiting the vast majority of all galaxies impossible. As Siegel puts it:
This simple statement puts a lot of things into perspective. When ET hunters posit a universe so vast that intelligent life must exist beyond our solar system, they may not be accounting for a paradigm where even the most technologically sophisticated beings in the universe are kept separate from us and each other through sheer force of the laws of physics.
Once a galaxy is too far away for a craft traveling at the speed of light to reach after an infinite amount of time, any species isolated in such a kingdom would be essentially alone in the universe.
So, what does that tell us about any trips to our next door neighbor Andromeda? If Einstein and the laws of physics are correct, nothing can travel faster than the speed of light. And that means that trip would take 2.537 million years at the universe’s speed limit.
Chances are, we won’t be meeting any space aliens unless they’re already in our own galaxy.