Mozilla needs your help to expose YouTube’s recommendation algorithm
YouTube‘s recommendation algorithm drives more than 70% of the videos we watch on the site. But its suggestions have attracted criticism from across the spectrum.

A developer who’s worked on the system said last year that it’s “toxic” and pushes users towards conspiracy videos, but a recent study found it favors mainstream media channels and actively discourages viewers from watching radical content.
Mine, of course, suggests videos on charitable causes, doctoral degrees, and ethical investment opportunities. But other users receive less noble recommendations.
If you’re one of them, a new browser extension from Mozilla could offer you some insights into the horrors lurking “Up next.”
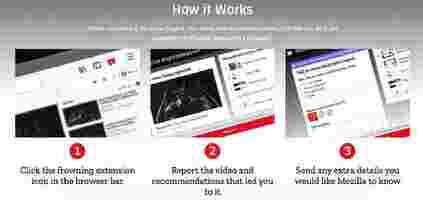
After installing the RegretsReporter and playing a YouTube video, you can click the frowning face icon in your browser to report the video, the recommendations that led you to it, and any extra details on “your regret.” Mozilla researchers will then search for patterns that led to the recommendations.
In a blogpost , Ashley Boyd, Mozilla’s VP of Advocacy & Engagement, gave three examples of what the extension could uncover:
What type of recommended videos lead to racist, violent, or conspiratorial content?
Are there patterns in terms of frequency or severity of harmful content?
Are there specific YouTube usage patterns that lead to harmful content being recommended?
“We ask users not to modify their YouTube behavior when using this extension,” said Boyd. “Don’t seek out regrettable content. Instead, use YouTube as you normally do. That is the only way that we can collectively understand whether YouTube’s problem with recommending regrettable content is improving, and which areas they need to do better on.”
Boyd said Mozilla built the extension after spending a year pressurizing YouTube to give independent researchers access to its recommendation data. The company has acknowledged that the algorithms can lead users to harmful content, but is yet to release the data.
Rather than continue waiting, Mozilla wants to “turn YouTube users into watchdogs” who will offer their recommendation data for investigation. The company says it will share the findings publicly, and hopes YouTube will use the information to improve its products.
A YouTube spokesperson said the company welcomed more research on this front, but questioned Mozilla’s methodology for the project:
Mozilla promises that all the data it collects is linked to a randomly-generated user ID, rather than your YouTube account, and that no one else will have access to the raw data. So your secret love of Alex Jones should be safe for now.
New self-supervised AI models scan X-rays to predict prognosis of COVID-19 patients
Researchers from Facebook and NYU Langone Health have created AI models that scan X-rays to predict how a COVID-19 patient’s condition will develop.
The team says that their system can forecast whether a patient may need more intensive care resources up to four days in advance. They believe hospitals could use it to anticipate demand for resources and avoid sending at-risk patients home too early.
Their approach differs from most previous attempts to predict COVID-19 deterioration by applying machine learning techniques to X-rays.
These typically use supervised training and single timeframe images. This method has shown promise, but its potential is constrained by the time-intensive process of manually labeling data.
These limits led the researchers to use self-supervised learning instead.
They first pre-trained their system on two public X-ray datasets, using a self-supervised learning technique called Momentum Contrast (MoCO). This allowed them to use a large quantity of non-COVID X-ray data to train their neural network to extract information from the images.
Predicting COVID-19 deterioration
They used the pre-trained model to build classifiers that predict if a COVID-19 patient’s condition will likely worsen. They then fine-tuned the model with an extended version of the NYU COVID-19 dataset.
This smaller dataset set of around 27,000 X-ray images from 5,000 patients was given labels indicating whether the patient‘s condition deteriorated within 24, 48, 72, or 96 hours of the scan.
The team built one classifier that predicts patient deterioration based on a single X-ray. Another makes its forecasts using a sequence of X-rays, by aggregating the image features through a Transformer model. A third model estimates how much supplemental oxygen patients might need by analyzing one X-ray.
They say using a sequence of X-rays is particularly valuable, as they’re more accurate for long-term predictions. This approach also accounts for the evolution of infections over time.
Their study showed the models were effective at predicting ICU needs, mortality forecasts, and overall adverse event predictions in the longer-term (up to 96 hours):
You can read the study paper on the preprint server Axirg.
GitHub’s new AI tool doesn’t violate copyrights, says expert
Last week, GitHub launched a new AI-powered tool called Copilot that’s meant to help developers out by suggesting snippets of code automatically.
The tool was developed in conjunction with OpenAI by training the system on publically available source code of different projects. On paper, this feels like any other AI project’s training method. But several people took to Twitter criticizing GitHub’s move and calling it a copyright violation.
However, Julia Reda — researcher and former Member of the European Parliament — has argued on her blog that GitHub’s too l doesn’t violate copyrights .
She also added that text and data mining is not against copyright laws. Plus, machine-generated work — in this case, code snippets generated by the Copilot tool — can’t be called derivative work, and is not covered under intellectual property rules:
There’s a lot of debate going on around the world related to tweaking IP-related policies when it comes to machine-generated work, but it’ll take a while till these arguments will be put to bed. In the meantime, you’ll just have to keep tweeting out your frustrations.