Samsung’s new phone has a 2.5 mm quantum random number generator for improved security
Samsung partnered with SK Telecom to create the device, which is currently only available in Korea . The network operator said in a press release that the QRNG chip will be used to generate random numbers and patterns to secure applications used for finance, messaging, and authentication.

The carrier company has already onboarded a bunch of partners including, banks like Standard Chartered and Shinhan. Plus, SK Telecom’s own services like T-pass and Samsung’s payment system are secured by this method.
SK Telecom is no stranger to QRNG chips. In 2016, the firm researchers published a detailed paper describing the function and utility of its 5mm square chip. It used a phone camera to measure fluctuations in an LED’s intensity to generate random numbers.

A large number of encryptors use the RSA method of multiplying prime numbers and generating a public encryption key and a private decryption key out of it. While this method might be hard to crack at the moment, quantum computers of the future may not have this problem . To overcome that hurdle, researchers have thought of QRNG methods to generate complex numbers at a breakneck speed to keep the security intact.
While including a QRNG chip might seem an extreme use case for a few high-security applications, a hack like Jeff Bezos’ leaked WhatsApp messages might remind us of the need for safer platforms.
The Galaxy Quantum 2 is powered by Snapdragon 855+ and has a 6.7-inch QHD display. The phone goes for pre-sale in Korea from April 13.
YouTube is testing AI-generated video chapters
YouTube‘s video chapters could soon get a time-saving AI upgrade. The streaming giant recently started testing using machine learning to automatically add chapters to videos.

The company announced the trial on the YouTube test features and experiments page o f the Google Support website :
The system could be a welcome addition to video chapters, which YouTube rolled out to creators in May.
The feature allows creators to break up videos into sections with their own individual previews. Viewers can then skip straight to the segment they want to watch.
YouTube says that when chapters are enabled, viewers watch more of the video and are more likely to come back to it. But creators currently have to manually add the timestamps to their video descriptions. Auto-generating the chapters would save them the trouble — as long as it organizes the content effectively.
If your videos are among those being tested, you can offer feedback on the process or opt-out of the experiment here .
HT – 9to5Google
IBM commits high-scale inference platform ModelMesh to open source
IBM today announced it has committed its ModelMesh inference service to open source. This is a big deal for the MLOps and DevOps community, but the implications for the average end-user are also huge.
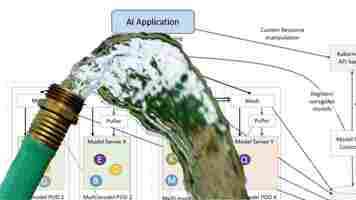
Artificial intelligence is a backbone technology that nearly all enterprises rely on. The majority of our coverage here on Neural tends to discuss the challenges involved in training and developing AI models.
But when it comes to deploying AI models so that they can do what they’re supposed to do when they’re supposed to do it, the sheer scale of the problem is astronomical.
Think about it: you log in to your banking account and there’s a discrepancy. You tap the “How can we help?” icon at the bottom of your screen and a chat window opens up.
You enter a query such as “Why isn’t my balance reflecting my most recent transactions?” A chat bot responds with “One moment, I’ll check your account,” and then, like magic, it says “I’ve found the problem” and gives you a detailed response concerning what’s happened.
What you’ve done is sent an inference request to a machine learning model. That model, using a technique called natural language processing (NLP), parses the text in your query and then sifts through all of its training data to determine how best it should respond.
If it does what it’s supposed to in a timely and accurate manner, you’ll probably walk away from the experience with a positive view on the system.
But what if it stalls or doesn’t load the inferences? You end up wasting your time with a chat bot and still need your problem solved.
ModelMesh can help.
Animesh Singh, IBM CTO for Watson AI & ML Open Tech, told Neural:
Going back to our banking customer analogy, we know that we’re not the only user our bank’s AI needs to serve inferences to. There could be millions of users querying a single interface simultaneously. And those millions of queries could require service from thousands of different models.
Figuring out how to load all these models in real-time so that they can perform in a manner that suits your customer’s needs is, perhaps, one of the biggest challenges faced by any company’s IT team.
ModelMesh manages both the loading and unloading of models to memory to optimize functionality and minimize redundant power consumption.
Per an IBM press release:
You can learn more about ModelMesh here on IBM’s website .